Your trigonometric teahcher must have told you given two vectors
, their
angle can be readily obtained by taking their dot product devided by
their product of norms:
Well, it's mathematically correct but there is some difference for
computers: numerical stability. For a very small angle, in which case
the two vectors are almost parallel, the result of
can be very close to 1, and the derivative of at , approaches infinity. This means that
even a small precision loss in
can result in huge precision loss after is applied.
Suppose the mathematically authentic value of
is , and the floating-number
represented in computer is where is small enough. Then, the
relative error can be written as:
When approaches , the relative error grows to infinity
even if is fixed. With
that being said, the precision loss embedded in the input number
is magnified by the function that transforms the number. We
call this numerical instability extrinsic
instability.
Catastrophic Cancellation
According to Wikipedia,
catastrophic cancellation is when subtracting approximations to two
close floating values may yield a bad approximation to the difference of
the original numbers.
Image the two real numbers are , and their rounded floating numbers are and , where and can be relatively small. Their
relative error, however, can be arbitrarily large:
The relative error
is fixed if , but
this is not generally possible in practice. If , and , and assume
,
we can estimate the relative error as follows:
This shows that if and are close enough, the relative error
can be large, much larger than . But note that the catastrophic
cancellation issue is only related to relative error,
not absolute error. This means that even if the
relative error is very large, the absolute error can be very small
relative to the operand's own magnitude. We care about the relative
error because it's highly related to the precision of the significand.
For example, assume the actual number is and the
floating-point representation is . The
latter loses half precision of the significand, but the absolute error,
scaled down by a factor of ,
is very small.
So what about other arithmetics like addition, multiplication and
division? Let's examine them.
For addition:
We can see that addition is bounded as long as is not close to . Next we test the relative error of
multiplication.
which is tightly bounded.
You can also check division is also bounded by the relative error
introduced from each floating number operand.
As an example for subtraction, consider calculating the following
value when is small enough ():
By calculus knowledge we know that , but due to
precision loss of when
, the value of will be 0, and zero divided by
a non-zero value is zero itself.
Matt
Pharr's post gives another great example illustrating this problem.
Due to the 32-bit floating point representation, the multiplication of
two large floating number will be rounded up at the base of . This tells us that the
floating number naturally comes with precision loss, but when we do the
calculation properly, the precision loss can be significantly mitigated.
The general idea is try to maintain precision for each expression and
not leave subtraction to the final step.
We call the numerical instability brought by floating number
representation as intrinsic instability. This post
discusses extrinsic instability for most of the time. For more details
about intrinsic instability, or catastrophic cancellation, I recommend
reading Bruce
Dawson's post about floating numbers.
Four Ways to
Compute Angles Between Vectors
There are four popular ways to compute the angle between two vectors
including the unstable trivial one introduced at the beginning.
Equation is simply an
equivalent representation of equation as , where
in this case.
To prove the correctness of equation , just note that
and .
To prove the correctness of equation (and thus equation ), we can assume and are both normalized without
loss of generality. Then
and .
Their fraction is:
Proof completes.
Mathematical Analysis
According to which type of instability is chosen, we can analyze and
compare the relative error of each method. In the following sections, we
use to denote the
floating point representation of the exact input value.
Extrinsic Relative Error
In extrainsic relative error analysis, we assume the overall input
has a fixed relative error: where
.
For the first method, the extrinsic relative error is:
When , the second term
would approach infinity. The extrinsic relative error of method one is
unbounded.
Now let's examine the second method. It's extrinsic relative error
is:
Note that when
, so the second term is
bounded and thus the extrinsic relative error of the second/third/forth
method is bounded.
Intrinsic Relative Error
Evaluating the instrinsic relative error is much more difficult. We
use to
represent the floating-point representation of any exact value , with its relative error . The
following notations are used in this section:
Note that:
Each ratio is bounded within , so we can rewrite it as
where . The ratio of product to product can be expressed
as:
For ,
we notice that:
The intrinsic relative error of the first method is:
It's obvious that can approach
infinity when .
Therefore, the instrinsic relative error of the first method is
unbounded when .
Let's go on to the second method:
The next step is to evaluate the ratio of two tangents, but its not
as easy as expected. We then turn to evaluate their cosines and sines
separately.
When , the ratio is
unbounded. When ,
the ratio can also be potentially super large. But it's worth noting
that as is generally very
small and
is very close to 1, a significantly small value of is required to ensure the ratio
unbounded. Due to the limited precision, the ratio is more likely to be
bounded at a slightly large value.
Next let's evaluate the third method. For brevity, we use the
following notations:
Then we can calculate the relative error as follows:
The relative error can approach infinity when , but is well bounded when
. Just as
explained in the second method, the relative error will be more likely
to be bounded at a slightly large value when .
In fact, the forth method has the exact same order of magnitude of
relative error as the third method. Just notice that:
where is a
normalized vector. Substituting into the third method and we will get the
same expression. Therefore, the relative error can approach infinity
when .
Overall, the extrinsic and intrinsic relative error of each method
can be summarized in the next table, where means stable (bounded), means unstable (unbounded) and means theoretically unbounded but
practically bounded. The left symbol of indicates the stability when the
angle approaches , and the right
symbol indicates when the angle approaches . For example, means the method is unstable when
angle approaches but stable when
angle is close to .
Method 1
Method 2
Method 3
Method 4
Extrinsic
Intrinsic
Experiments
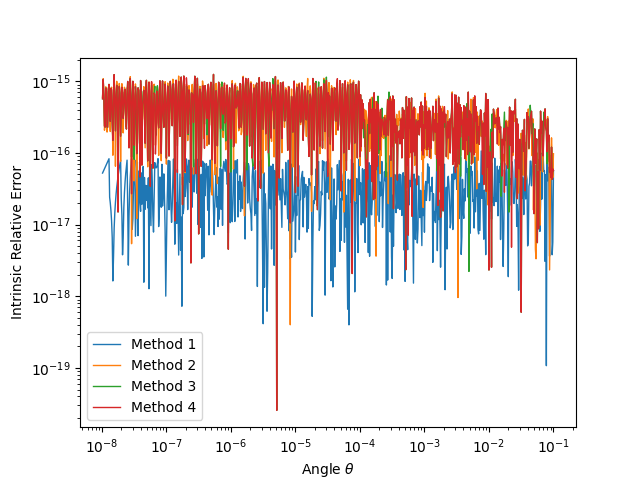
First we evaluate the instrinsic relative error of each method (code
is available at here). Results for
are shown in the next
figure.
The first method is well bounded whereas the other three methods have
a relatively large bounding value. This aligns with our conjecture that
within the limited precision, the intrinsic relative error of the latter
three methods comes with decent stability. As the angle gets much
smaller, the relative error should be infinite.
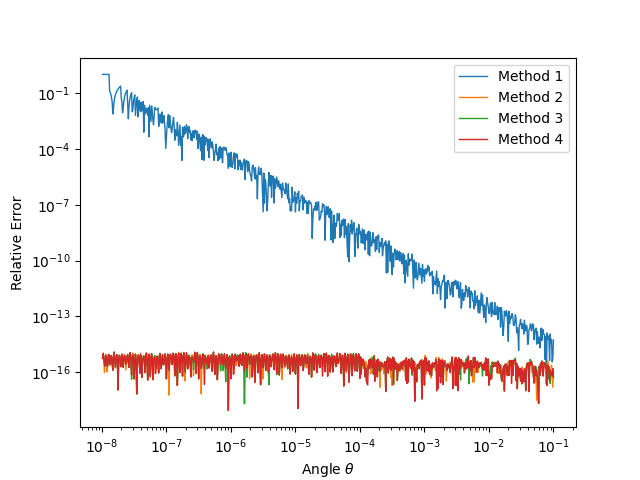
The following figure shows results for .
As expected, the first and second method has unbouned value and the
third and forth method is well bounded.
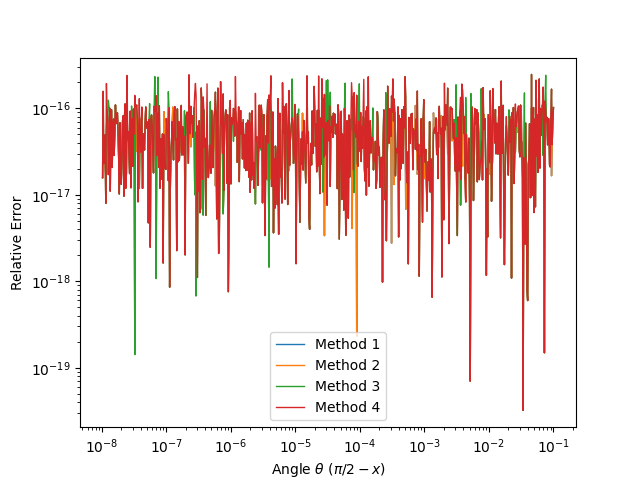
The following two figures respectively show the results for the
overall relative errors for and .
Only the first method has an unbounded relative error when due to its infinite extrinsic
relative error as .
Conclusion
Never use to
compute the angle between vectors! Use to get a numerically
stable result. Compared to intrinsic relative errors, the extrinsic
relative error seems to make the greatest difference on the stability
and even if the intrinsic relative error is unbounded, you can still
practically obtain a numerically stable result with . If you do care about the
intrinsic relative error, the third or forth method is all you need.
References
Floating-point numbers and catastrophic
cancellation
https://en.wikipedia.org/wiki/Catastrophic_cancellation
https://randomascii.wordpress.com/2012/02/25/comparing-floating-point-numbers-2012-edition/
https://pharr.org/matt/blog/2019/11/03/difference-of-floats
Angle between two vectors
https://scicomp.stackexchange.com/questions/27689/numerically-stable-way-of-computing-angles-between-vectors
https://math.stackexchange.com/questions/1143354/numerically-stable-method-for-angle-between-3d-vectors/1782769#1782769
Appendix
I find it very interesting to ask this question: how many digits in
the decimal form are required to fully express a 32-bit floating number
smaller than ?
For example, the floating number uses two decimal digits to
express the floating number since it can be written as . The floating number
uses three decimal
digits because it's . More generally, any floating number can be represented in either the binary
way or decimal way:
The binary representation is converted from the floating number's
internal bit-wise representation assuming precision under the 32-bit IEEE standard. When
the exponential field is non-zero, an implied leading one is added, just
as shown in the above binary representation. When the exponential field
is zero, there is no leading one, so the binary representation
becomes:
Okay, let's go back to our question. To determine the digits for any
floating number, we can first resolve a simpler case for floating
numbers in the form of . It's
very obvious that, the total number of digits of the plain decimal
representation for before
normalization, is exactly . For
example, has two digits,
has six digits, both
including the leading zeros. Then, if we use this number to subtract the
number of zeros, we will get the answer we need.
How many leading zeros are there in the decimal form of ? The question is equivalent to
finding the smallest integer such
that . We can
transform this inequality:
Hence, the number of decial digits needed to precisely represent
is .
We can then fully express in the
decimal form using this result:
We can test this result with some examples. When , the result is , correct. When , the result is , correct. When , i.e., , the result is , correct.
With this formula, we know that the maximum number of digits to
represent a -like floating
number in the decimal form is when , and this number is . When , the binary representation of that
floating number has zero in the exponential field and one in the
significant field, that is, . Everything is perfect.
What about a general floating number? You may think: oh it's easy,
just take the maximum count of all that contribute to the floating
number and that's the answer! Unfortunately, that's not the case. Take
as an example. The
decimal representation is , for which we must use up to
digits to represent it, rather
than - the digit count for , nor - the digit count for .
This happens because the number of leading zeros for each is different. When a adds to , the leading zeros can be filled,
thus increasing the valid digits.
We can first decompose into a
series of addition:
Then it's equivalent to a series of addition of:
Because
is a non-decreasing function, we can rearrange these floating numbers
as:
The number of decimal numbers to represent the sum of these floating
numbers depends only on because is also non-decreasing and adds the most leading
zeros. When adds to
, the first digit, which
is of makes sures all digits after
is valid, that is, needed to
represent the floating number. The final result is thus:
But not all s are , so in practice we first need to find
the largest index
such that , and we can
compute the result by .
What is maximum value of among all floating
numbers? Note that and are independent, so we can take the
largest and the largest and the result is . This floating
number has a zero exponential field and all-one significant field, i.e.,
the largest floating value smaller than .